Statistical Foundations
Imagine you are trying to find a lost set of keys in a large, dark house. You do not search every single inch of the floor randomly because that would take far too long. Instead, you check the places where you usually set them down, like the kitchen counter or the hallway table. Archaeologists use this same logic when they look for ancient sites in a vast landscape. They do not dig everywhere, because that would be a massive waste of time and money.
The Logic of Site Distribution
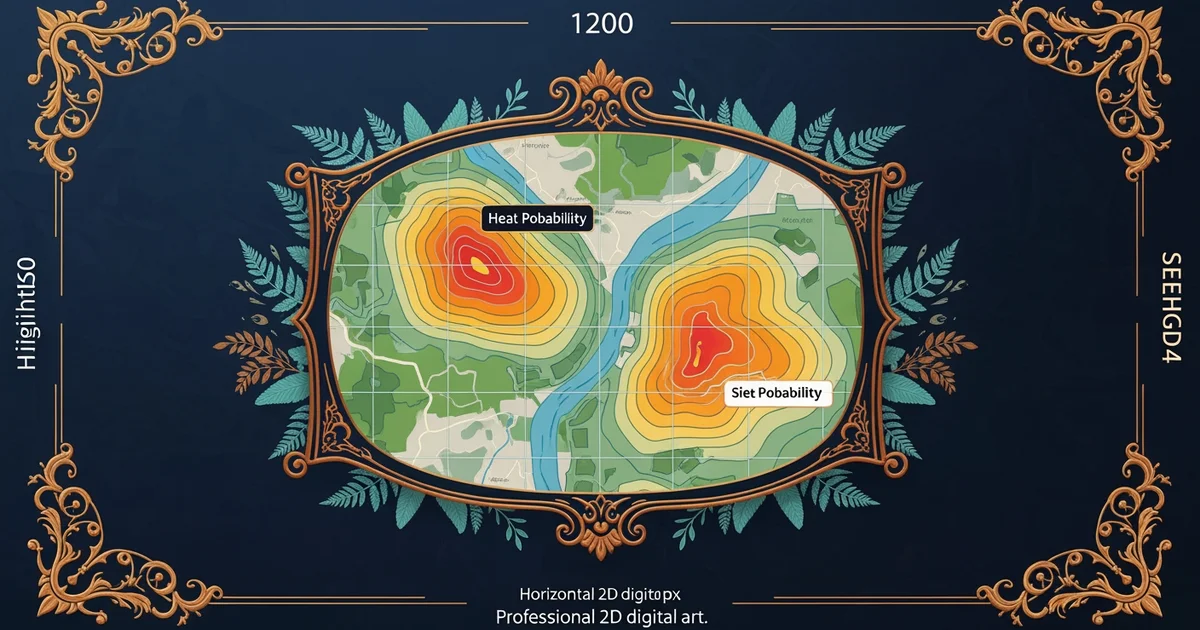
Archaeology relies on statistical probability to narrow down where human groups lived in the past. This concept suggests that past people chose to settle in areas that offered the best resources for their survival. If we find that ancient people preferred flat land near fresh water, we can assign a higher probability to finding sites in those specific areas. We treat the landscape as a series of data points where certain features increase the likelihood of human activity. By measuring how often sites appear near water, hills, or forests, we build a model of past behavior.
Think of this process like a store owner predicting which items will sell best during the holiday season. The owner looks at past sales data to decide which products to stock on the front shelves. If the data shows that customers always buy winter coats in November, the owner will prioritize those items over swimming trunks. Similarly, archaeologists look at the patterns of where people lived before to predict where they will find new sites today. This helps them focus their limited resources on areas that have the highest potential for discovery.
Key term: Statistical probability — a mathematical way to estimate the chance that a specific event or feature will occur in a given area.
Analyzing Spatial Patterns
Once we identify these patterns, we must translate them into a format that allows us to make predictions. We divide the landscape into small, manageable squares to count the number of sites found in each type of environment. This method allows us to calculate the density of sites across different zones. If a specific zone has a high density of sites, we classify it as a high-potential area for future research. This numerical approach turns vague guesses into a structured plan that guides our fieldwork.
To organize this data, we often compare environmental variables against the number of sites discovered. This table illustrates how different landscape features influence our search strategy for finding ancient settlements:
| Landscape Feature | Site Presence | Predictive Value |
|---|---|---|
| Near River Bank | Very High | Primary Target |
| Dense Forest | Low | Low Priority |
| Open Grassland | Moderate | Secondary Target |
| Rocky Mountain | Very Low | Ignore |
This table shows how we prioritize our search efforts based on known patterns. We do not ignore low-probability areas entirely, but we focus our main budget on the high-value zones. By using these simple math tools, we reduce the risk of searching in places where humans likely never lived. This creates a more efficient path to uncovering the history buried beneath our feet.
When we combine these observations, we can calculate the odds of finding a site in any new, unexplored area. We take the number of known sites in a specific environment and divide it by the total area of that environment. This gives us a simple percentage of success that guides our next steps. If the math says there is a thirty percent chance of finding a site near a river, we know that is a good place to start digging. This process removes the guesswork from archaeology and replaces it with clear, evidence-based strategy.
Predictive modeling uses past settlement patterns to calculate the likelihood of finding undiscovered sites in similar environmental conditions.
The next Station introduces GIS and Spatial Analysis, which determines how these statistical models are mapped across physical terrain.